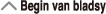Statistiese berekeninge (STAT)
Om 'n statistiese berekening te begin, voer die insleuteling 
 (STAT) uit om na die STAT-modus te verander, en gebruik dan die skerm wat verskyn om die tipe berekening te kies wat ingesleutel moet word.
(STAT) uit om na die STAT-modus te verander, en gebruik dan die skerm wat verskyn om die tipe berekening te kies wat ingesleutel moet word.
Om hierdie tipe statistiese berekening te selekteer: (Regressieformule tussen hakies vertoon) |
Druk hierdie sleutel: |
|---|---|
| Enkele veranderlike (X) |  (1-VAR) (1-VAR) |
| Gepaarde veranderlike (X; Y), lineêre regressie (y = A + Bx) |
 (A+BX) (A+BX) |
| Gepaarde veranderlike (X; Y), kwadratiese regressie (y = A + Bx + Cx2) |
(_+CX2) |
| Gepaarde veranderlike (X; Y), logaritmiese regressie (y = A + Blnx) |
 (ln X) (ln X) |
| Gepaarde veranderlike (X; Y), e-eksponensiële regressie (y = A eBx) |
 (e∧X) (e∧X) |
| Gepaarde veranderlike (X; Y), ab-eksponensiële regressie (y = ABx) |
 (A•B∧X) (A•B∧X) |
| Gepaarde veranderlike (X; Y), magsregressie (y = AxB) |
 (A•X∧B) (A•X∧B) |
| Gepaarde veranderlike (X; Y), inverse regressie (y = A + B/x) |
 (1/X) (1/X) |
Druk enige van die sleutels hier bo ( tot ) om die statistiese redigeerder te vertoon.
Neem kennis
Om die berekeningtipe te verander nadat daar na die STAT-modus verander is, voer die insleuteling  (STAT/DIST)(Type) uit om die berekeningstipe-skerm te vertoon.
(STAT/DIST)(Type) uit om die berekeningstipe-skerm te vertoon.
Om data in te voer
Gebruik die statistiese redigeerder om data in te sleutel. Voer die volgende insleuteling uit om die statistiese redigeerder te vertoon: (STAT/DIST)(Data).
Die Statistiekredigeerder gee 40 rye vir datainsleutel waar daar net 'n X-kolom is of wanneer daar 'n X- en 'n Y-kolom is, 20 rye wanneer daar 'n X- en FREQ-kolom is of 26 rye wanneer daar 'n X-, Y- en FREQ-kolom is.
Neem kennis
Gebruik die FREQ- (frekwensie) kolom om die hoeveelheid (frekwensie) identiese data-items in te sleutel. Die FREQ-kolom kan aangeskakel word (vertoon word) of afgeskakel word (versteek word) met die Stat Format-instelling in die opstellingskeuselys.
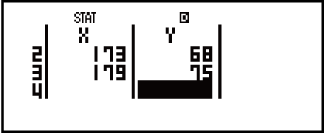
Voorbeeld 1: Om linieêre regressie te selekteer en die volgende data in te sleutel: (170; 66), (173; 68), (179; 75)
- (STAT)(A+BX)
- 170
 173179
173179

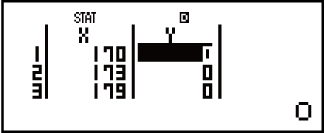
- 666875
Belangrik!
Alle data wat tans in die statistiese redigeerder ingesleutel is, word uitgewis wanneer die STAT-modus verlaat word, wanneer tussen die statistieseberekening-tipe vir enkele veranderlikes en gepaarde veranderlikes oorgeskakel word, of wanneer die Stat Format-instelling op die opstellingskeuselys verander word.
Die volgende operasies werk nie in die statistiese redigeerder nie:  , (M-),
, (M-),  (STO). Pol, Rec, ÷R en multistellings kan ook nie met die statistiese redigeerder ingesleutel word nie.
(STO). Pol, Rec, ÷R en multistellings kan ook nie met die statistiese redigeerder ingesleutel word nie.
Om die data in 'n sel te verander:
In die statistiese redigeerder, beweeg die wyser na die sel wat die data bevat wat verander moet word, sleutel die nuwe data in, en druk dan .
Om 'n reël uit te wis:
In die statistiese redigeerder, beweeg die wyser na die reël wat uitgewis moet word, en druk dan  .
.
Om 'n reël in te voeg:
In die statistiese redigeerder, beweeg die wyser na die plek waar die reël ingevoeg moet word, en voer dan die volgende insleuteling uit:
(STAT/DIST)(Edit)(Ins).
Om alles in die Statistiekredigeerder uit te wis:
In die statistiese redigeerder, voer die volgende insleuteling uit:
(STAT/DIST)(Edit)(Del-A).
Skerm vir statistiese berekeninge
Die statistieseberekening-skerm is bedoel om statistiese berekeninge met data wat met die statistiese redigeerder ingesleutel is, uit te voer. Wanneer die  -sleutel gedruk word terwyl die statistiese redigeerder vertoon word, skakel dit om na die statistieseberekening-skerm.
-sleutel gedruk word terwyl die statistiese redigeerder vertoon word, skakel dit om na die statistieseberekening-skerm.
Om die Statistiek-keuselys te gebruik
Terwyl die statistieseberekening-skerm vertoon word, druk (STAT/DIST) om die Statistiek-keuselys te vertoon.
Die inhoud van die Statistiek-keuselys wissel na gelang die huidige gekose statistiesebewerking-tipe 'n enkele veranderlike of gepaarde veranderlikes gebruik.
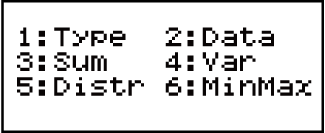
Enkelveranderlike-statistiek
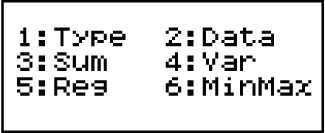
Gepaardeveranderlike-statistiek
Statistiek-keuselys-items
Algemene items
| Selekteer hierdie keuselys-item: | Om dit in te verkry: |
|---|---|
| (Type) |
Vertoon die seleksieskerm vir berekeningstipe |
| (Data) |
Vertoon die statistiese redigeerder |
| (Sum) |
Vertoon die Sum-subkeuselys se bevele om somme te bereken |
| (Var) |
Vertoon die Var-subkeuselys se bevele om die rekenkundige gemiddelde, standaard-afwyking, ens. te bereken |
| Enkele veranderlike: (Distr) |
Vertoon die Distr-subkeuselys se bevele vir normaleverspreiding-berekeninge • Vir meer inligting, kyk "Uitvoer van normaleverspreidingsberekeninge". |
| Gepaarde veranderlike: (Reg) |
Vertoon die Reg-subkeuselys se bevele vir regressieberekeninge • Vir meer inligting, kyk "Bevele wanneer lineêreregressie-berekening (A + BX) geselekteer is" en "Bevele wanneer kwadratieseregressie-berekening (_+CX2) geselekteer is". |
| (MinMax) |
Vertoon die MinMax-subkeuselys se bevele om maksimum- en minimum-waardes te verkry |
Enkele veranderlike (1-VAR) se bevele vir statistiese berekeninge
Sum-subkeuselys ((STAT/DIST)(Sum))
| Selekteer hierdie keuselys-item: | Om dit in te verkry: |
|---|---|
| (∑x2) |
Som van kwadrate van die voorbeelddata |
| (∑x) |
Som van die voorbeelddata |
Var-subkeuselys ((STAT/DIST)(Var))
| Selekteer hierdie keuselys-item: | Om dit in te verkry: |
|---|---|
| (n) |
Aantal voorbeelde |
| (x) |
Rekenkundige gemiddeld van die voorbeelddata |
| (σx) |
Populasie se standaardafwyking |
| (sx) |
Voorbeeld se standaardafwyking |
Distr-subkeuselys ((STAT/DIST)(Distr))
| (P() |
Hierdie keuselys kan gebruik word om die waarskynlikheid van standaard-normale verspreiding te bereken. • Vir inligting, kyk "Uitvoer van normaleverspreidingsberekeninge". |
| (Q() |
|
| (R() |
|
( t) t) |
MinMax-subkeuselys ((STAT/DIST)(MinMax))
| Selekteer hierdie keuselys-item: | Om dit in te verkry: |
|---|---|
| (minX) |
Minimum-waarde |
| (maxX) |
Maksimum-waarde |
| (Q1) |
Eerste kwartiel |
| (med) |
Mediaan |
| (Q3) |
Derde kwartiel |
Bevele wanneer lineêreregressie-berekening (A + BX) geselekteer is
Sum-subkeuselys ((STAT/DIST)(Sum))
| Selekteer hierdie keuselys-item: | Om dit in te verkry: |
|---|---|
| (∑x2) |
Som van kwadrate van die X-data |
| (∑x) |
Som van die X-data |
| (∑y2) |
Som van kwadrate van die Y-data |
| (∑y) |
Som van die Y-data |
| (∑xy) |
Som van die produkte van die X-data en Y-data |
| (∑x3) |
Som van die derde magte van die X-data |
| (∑x2y) |
Som van (X-datakwadrate × Y-data) |
| (∑x4) |
Som van bikwadrate van die X-data |
Var-subkeuselys ((STAT/DIST)(Var))
| Selekteer hierdie keuselys-item: | Om dit in te verkry: |
|---|---|
| (n) |
Aantal voorbeelde |
| (x) |
Rekenkundige gemiddeld van die X-data |
| (σx) |
Populasie se standaardafwyking van die X-data |
| (sx) |
Voorbeeld se standaardafwyking van die X-data |
| (y) |
Rekenkundige gemiddeld van die Y-data |
| (σy) |
Populasie se standaardafwyking van die Y-data |
| (sy) |
Voorbeeld se standaardafwyking van die Y-data |
Reg-subkeuselys ((STAT/DIST)(Reg))
| Selekteer hierdie keuselys-item: | Om dit in te verkry: |
|---|---|
| (A) |
Regressiekoëffisiënt-konstante, term A |
| (B) |
Regressiekoëffisiënt B |
| (r) |
Korrelasiekoëffisiënt r |
| (xˆ) |
Geskatte waarde van X |
| (yˆ) |
Geskatte waarde van Y |
MinMax-subkeuselys ((STAT/DIST)(MinMax))
| Selekteer hierdie keuselys-item: | Om dit in te verkry: |
|---|---|
| (minX) |
Minimum-waarde van die X-data |
| (maxX) |
Maksimum-waarde van die X-data |
| (minY) |
Minimum-waarde van die Y-data |
| (maxY) |
Maksimum-waarde van die Y-data |
Bevele wanneer kwadratieseregressie-berekening (_+CX2) geselekteer is
Reg-subkeuselys ((STAT/DIST)(Reg))
| Selekteer hierdie keuselys-item: | Om dit in te verkry: |
|---|---|
| (A) |
Regressiekoëffisiënt-konstante, term A |
| (B) |
Lineêre koëffisiënt B van die regressiekoëffisiënte |
| (C) |
Kwadratiese koëffisiënt C van die regressiekoëffisiënte |
| (xˆ1) |
Geskatte waarde van x1 |
| (xˆ2) |
Geskatte waarde van x2 |
| (yˆ) |
Geskatte waarde van y |
Neem kennis
xˆ, xˆ1, xˆ2 en yˆ is nie veranderlikes nie. Dit is bevele van die tipe wat 'n argument direk voor dit neem. Kyk "Berekening van geskatte waardes" vir meer inligting.
Voorbeeld 2: Om die enkelveranderlike-data x = {1, 2, 2, 3, 3, 3, 4, 4, 5} in te sleutel, gebruik die FREQ-kolom om die aantal herhalings vir elk van die items ({xn; freqn} = {1;1, 2;2, 3;3, 4;2, 5;1}) te spesifiseer, en bereken die rekenkundige gemiddelde en populasie se standaardafwyking.
- (SETUP)(STAT)(ON)
(STAT)(1-VAR)
12345
1232 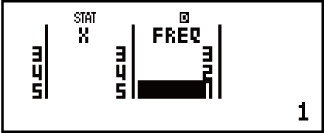
- (STAT/DIST)(Var)(x)
- 3
- (STAT/DIST)(Var)(σx)
- 1,154700538
Resultate: Rekenkundige gemiddeld: 3, populasie se standaardafwyking: 1,154700538
Voorbeeld 3: Om die lineêre regressie se logaritmiese regressie se korrelasiekoëffisiënte vir die volgende data met gepaarde veranderlikes te bereken en die regressieformule vir die sterkste korrelasie te bepaal: (x; y) = (20; 3150), (110; 7310), (200; 8800), (290; 9310). Stel sakrekenaar om af te rond tot drie desimale plekke (Fix 3).
- (SETUP)(STAT)(OFF)
(SETUP)(Fix)
(STAT)(A+BX)
20110200290
3150731088009310 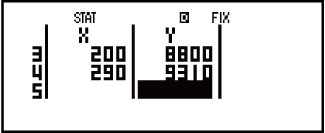
- (STAT/DIST)(Reg)(r)
- 0,923
- (STAT/DIST)(Type)(ln X)
(STAT/DIST)(Reg)(r) - 0,998
- (STAT/DIST)(Reg)(A)
- -3857,984
- (STAT/DIST)(Reg)(B)
- 2357,532
Resultate: Lineêre regressie se korrelasiekoëffisiënt: 0,923
Logaritmiese regressie se korrelasiekoëffisiënt: 0,998
Logaritmiese regressie se formule: y = -3857,984 + 2357,532lnx
Berekening van geskatte waardes
Op grond van die regressieformule wat deur statistiese berekening van gepaarde veranderlikes verkry is, kan die geskatte waarde van y vir 'n gegewe x-waarde bereken word.
Die ooreenstemmende x-waarde (twee waardes, x1 en x2, in die geval van kwadratiese regressie) kan ook vir 'n waarde van y in die regressieformule bereken word.
Voorbeeld 4: Om die geskatte waarde van x te bepaal wanneer y = -130 in die regressieformule wat deur die logaritmiese regressie van die data in Voorbeeld 3 geproduseer is. Spesifiseer Fix 3 vir die resultaat. (Voer die volgende bewerking uit na voltooiing van die bewerkings in Voorbeeld 3.)
 130(STAT/DIST)(Reg)(xˆ)
130(STAT/DIST)(Reg)(xˆ)- 4,861
Belangrik!
Regressiekoëffisiënt, korrelasiekoëffisiënt en geskattewaarde-berekeninge kan aansienlike tyd neem indien daar 'n groot aantal data-items is.
Uitvoer van normaleverspreidingsberekeninge
Terwyl statistiese berekening van enkele veranderlike geselekeer is, kan normaleverspreiding-berekeninge uitvoer word met die funksies hier onder wat in die keuselys verskyn wanneer die volgende insleuteling uitgevoer word: (STAT/DIST)(Distr).
P, Q, R: Hierdie funksies neem die argument t en bepaal die waarskynlikheid van standaard-normale verspreiding soos hier onder geïllustreer.
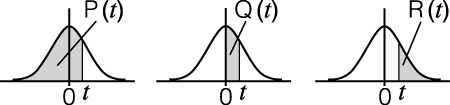
t: Hierdie funksie word voorafgegaan deur die argument X, en bepaal die genormaliseerde variaat Xt = X - xσx.
Voorbeeld 5: Vir die enkelveranderlike-data {xn; freqn} = {0;1, 1;2, 2;1, 3;2, 4;2, 5;2, 6;3, 7;4, 9;2, 10;1}, om die genormaliseerde variaat (t) te bepaal wanneer x = 3 en P(t) op daardie punt tot drie desimale plekke (Fix 3).
- (SETUP)(STAT)(ON)
(SETUP)(Fix)
(STAT)(1-VAR)
- 01234567910
1212223421 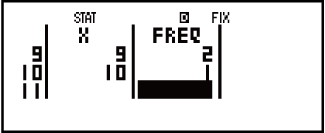
- 3(STAT/DIST)(Distr)(t)
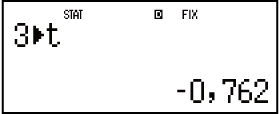
- (STAT/DIST)(Distr)(P()



Resultate: Genormaliseerde variaat (t): -0,762
P(t): 0,223